Writing
你寫了很多文章,卻沒有被搜尋引擎和 AI 工具穩定讀到
AI,Notion,Pipeline,Product,Notes
Created by Ronnie Wong on 2026/5/22
我最近在整理 RonnieCC Blog 時,遇到一個看起來很小、但其實會影響整個內容分發的問題:文章在網站上看得到,不代表它已經被搜尋引擎、sitemap、link preview 或 AI 工具穩定讀到。
如果只把這件事說成「Blog 靜態化」或「前端 SEO 最佳實踐」,文章會變得很薄。真正值得記錄的不是某個技術選型,而是一次內容系統演進後,發布責任沒有完整交接。
文章寫完不等於發布。發布也不等於被機器讀到。
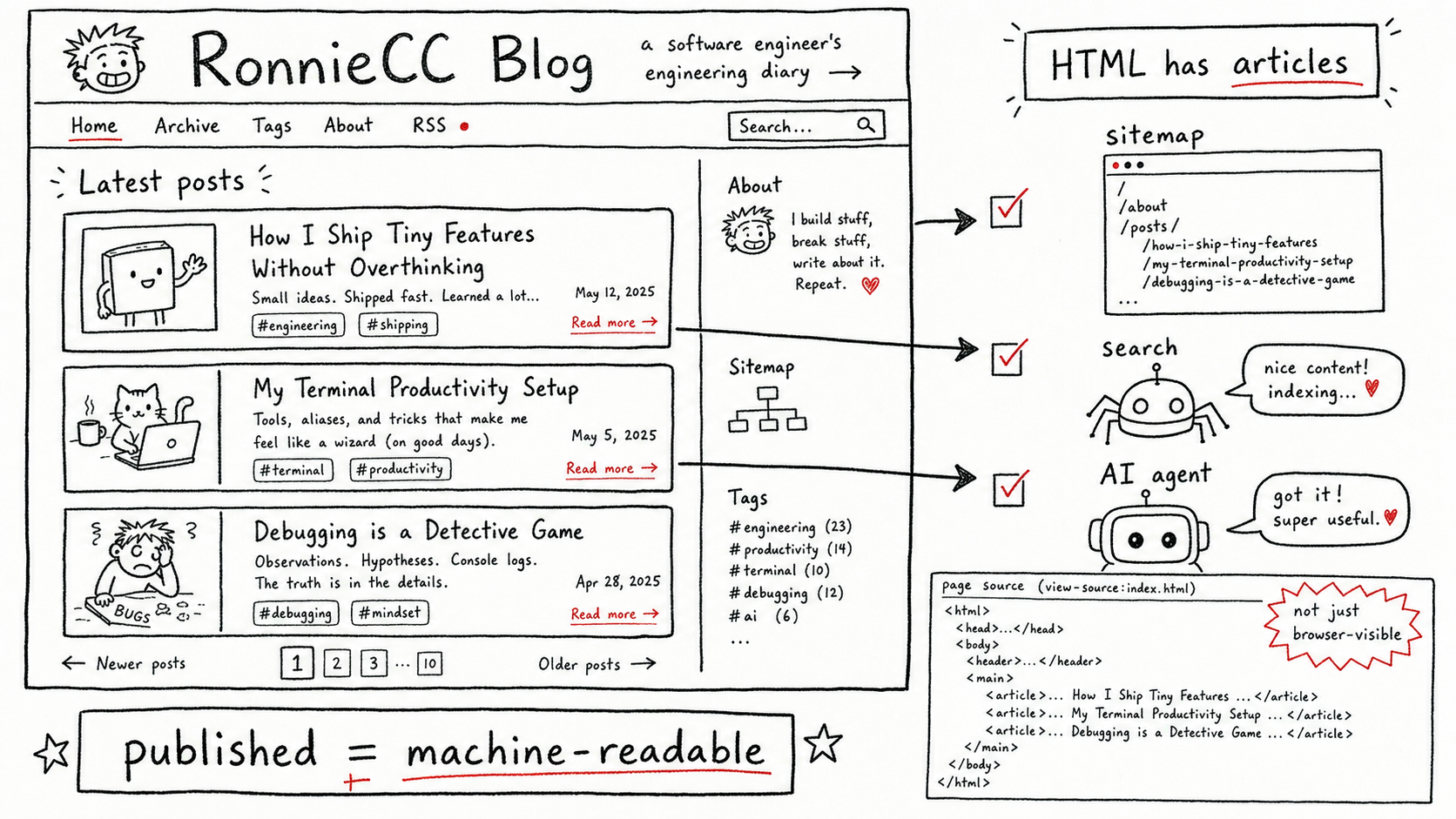
問題不是靜態化,而是責任沒有交接
RonnieCC Blog 的 v1 很簡單:列表頁放的是 Notion 文章跳轉地址。那個階段的責任邊界很清楚,RonnieCC 只是入口,Notion 才是實際閱讀頁。
後來我把 RonnieCC 往前推了一步:Notion 繼續做材料中心,但文章要進入 RonnieCC 站內閱讀。這個方向是對的,因為 RonnieCC 不應該只是把讀者送回 Notion。它應該成為正式的內容入口,承接搜尋、內鏈、引用和個人品牌沉澱。
問題出在這次重構之後。文章頁已經同步出來,Blog 頁面也能在瀏覽器裡看到列表,但 Blog index 的主要內容仍然偏向由瀏覽器端動態組出來。對人類讀者來說,頁面正常;但對只讀初始 HTML 的機器讀者來說,文章列表可能仍然不穩定。
也就是說,我不是從零開始忘了做靜態化,而是在 RonnieCC 從「Notion 外鏈入口」演進成「站內內容分發系統」時,沒有把 Blog list 的分發責任一起搬過來。
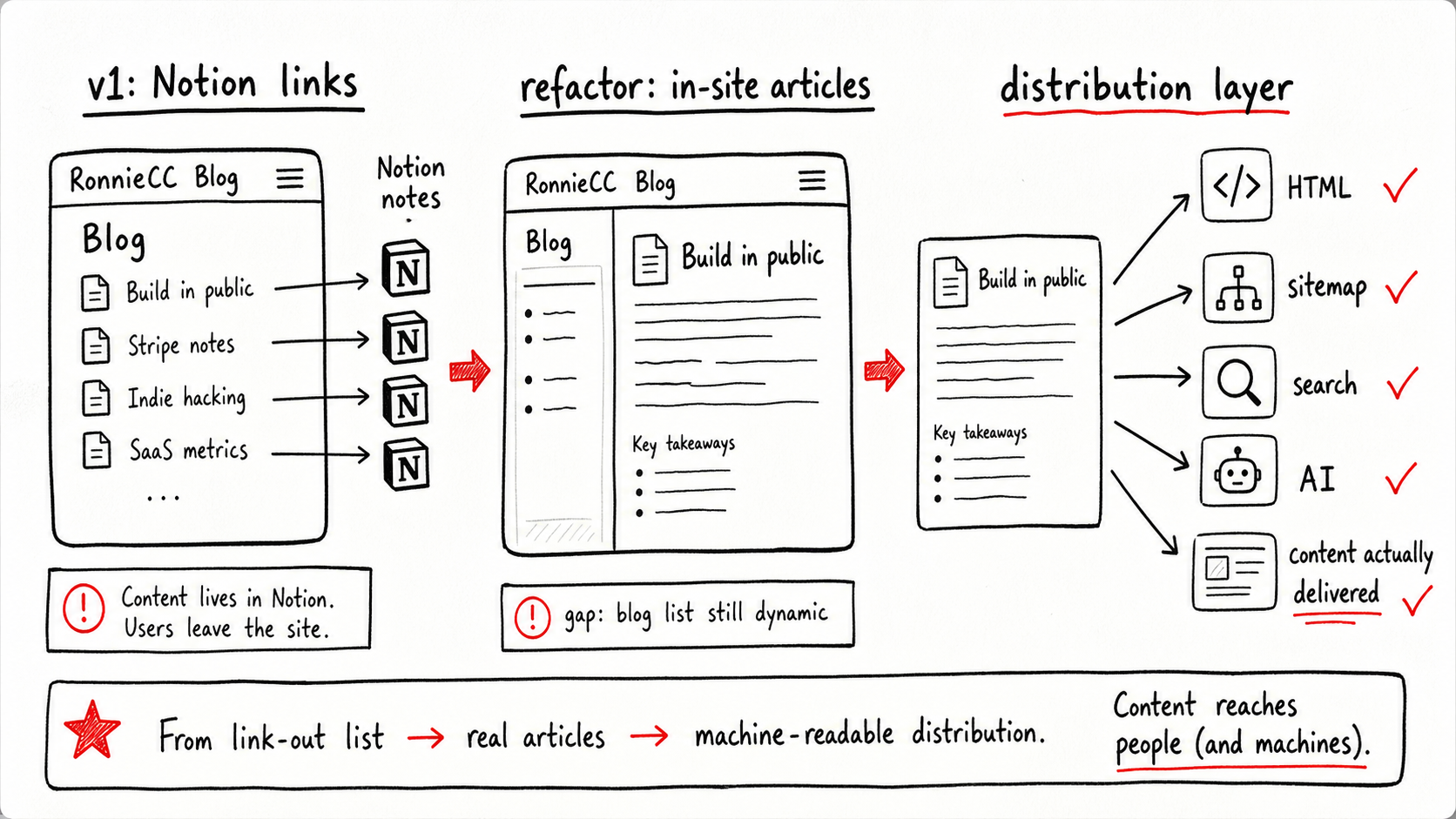
方法論一:內容移轉不是搬家,而是責任交接
這件事可以抽象成一個更通用的判斷框架:當內容從一個材料層移到公開分發層時,你不是只在搬文章,而是在交接責任。
材料層可以是 Notion、CMS、資料庫、Markdown repo 或後台 API。公開分發層則是讀者、搜尋引擎、社交預覽、RSS、sitemap、AI Agent 會接觸到的地方。內容一旦被宣稱「發布」,下面幾件事就應該跟著交出去:
- 權威 URL:這篇文章正式存在於哪個公開網址,而不是只存在於後台或 Notion。
- 發現入口:首頁、Blog index、內鏈、sitemap 是否都能指向它。
- 可讀內容:初始 HTML 裡是否有足夠的標題、連結、摘要或正文,讓不完整執行前端的讀者也能理解。
- 驗收回路:你是否能用 view-source、sitemap、Search Console、AI browser 這類外部視角確認它真的被交付。
如果這些責任沒有交接,文章就只是從一個地方被顯示到另一個地方,還沒有真正進入網路的分發系統。
方法論二:把機器讀者當成真實讀者
過去我們很容易把「讀者」理解成人類瀏覽器使用者。但公開網站不是只服務人類。只要你希望內容被搜尋、被引用、被 AI 工具讀取,就必須承認機器讀者也是讀者。
我會把這些機器讀者分成幾類來看:
- sitemap 與搜尋入口:它們需要穩定 URL、更新時間與可提交的索引結構。
- crawler 與 source reader:它們需要在初始 HTML 裡找到文章列表、標題與連結。
- link preview 與摘要工具:它們需要 metadata、標題、描述與可解析的頁面結構。
- AI Agent browser:它們不一定像完整瀏覽器一樣執行所有互動邏輯,因此需要簡單、語義清楚、可直接讀取的內容入口。
這個矩陣的用途,不是把每個網站都做成傳統靜態站,而是提醒自己:當一種機器讀者讀不到時,內容在某個分發面上就是缺席的。
方法論三:發布前問三個問題
所以我現在會把「發布」拆成三個更可驗收的問題。這三個問題不綁定任何框架,也不要求讀者先懂前端。
- 權威位置在哪裡?這篇文章最後應該被哪個公開 URL 代表,是 Notion、CMS,還是自己的網站?
- 發現路徑是否存在?Blog index、內鏈、sitemap、語言版本入口是否能把讀者帶到這篇文章?
- 有限能力讀者能不能讀到?不跑完整前端、不依賴登入、不依賴額外互動時,source、crawler 或 AI reader 是否仍能知道這篇文章存在?
如果第一問回答不清楚,問題通常是內容權威性混亂。如果第二問失敗,問題通常是分發入口沒有建好。如果第三問失敗,問題通常是內容只存在於 runtime,而沒有進入可被機器穩定讀取的層。
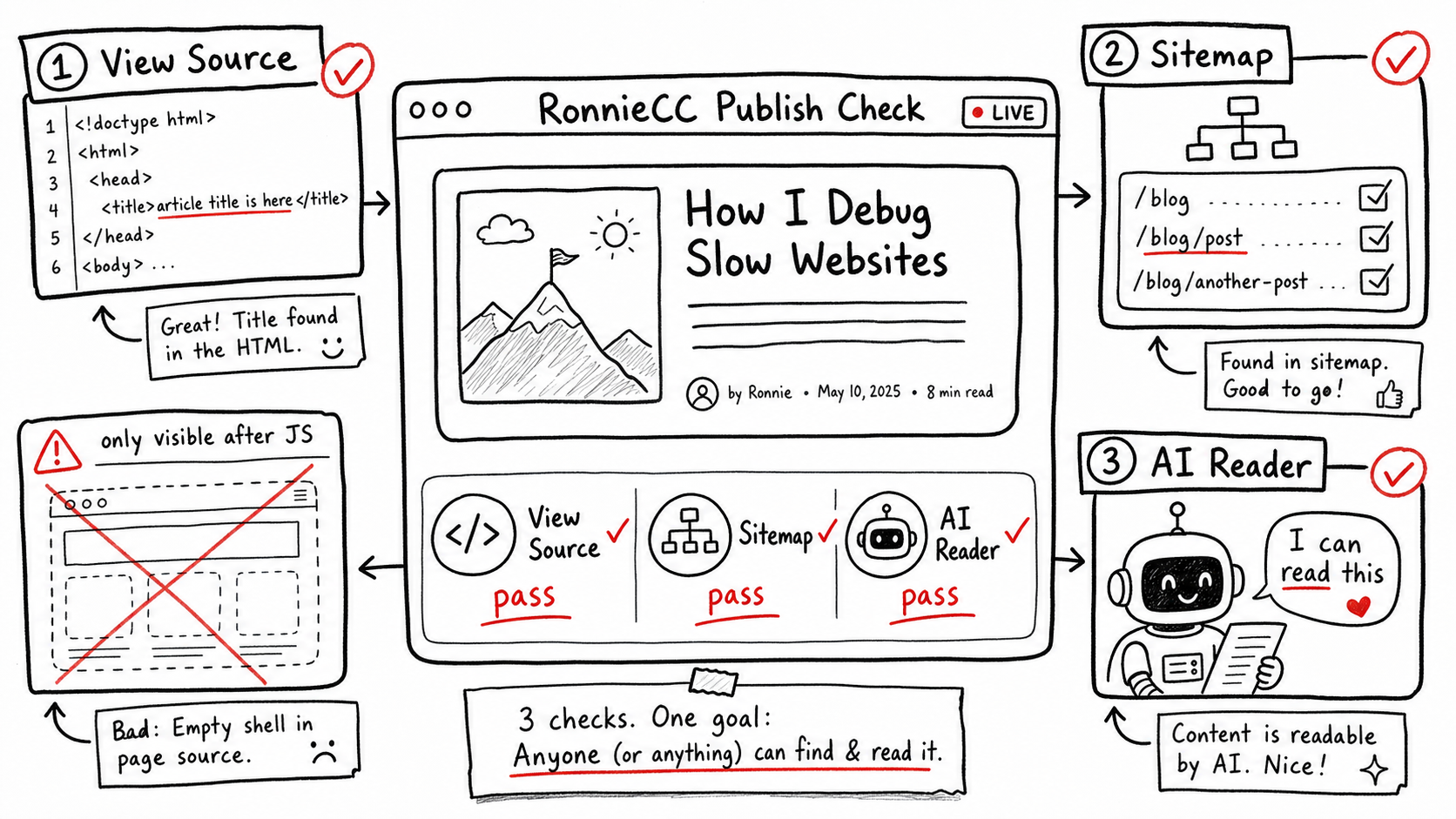
把 Blog index 變成分發契約
回到 RonnieCC,這次真正要修的不是「頁面好不好看」,而是 Blog index 的責任模型。Notion 負責收集和整理材料;RonnieCC 負責把內容正式交付到公開分發層。
因此正式發布後的 Blog 頁,HTML 本身就應該包含文章標題和文章連結。JavaScript 可以保留,但它只能是 fallback,不能是正式內容被看見的唯一方式。
這個決策把 Blog index 從一個瀏覽器互動頁,改回一個內容分發契約:它要讓人能讀,也要讓搜尋引擎、sitemap、預覽工具和 AI Agent 能確認 RonnieCC 到底發布了什麼。
意義:把文章變成公開知識物件
這件事對 RonnieCC 的意義,不只是「個人品牌資產要被搜尋到」。那個說法太淺。
更準確地說,RonnieCC 正在從一個展示個人經驗的網站,變成一個公開知識物件的生產與分發系統。當文章還在 Notion 裡,它是我的材料;當文章進入 RonnieCC,它就應該成為網路可以發現、引用、索引、摘要和再次使用的知識單位。
這會改變我對「完成」的定義。以前完成可能是寫完、排好版、瀏覽器裡看起來正常。現在完成還要包含:這篇文章是否有權威 URL,是否能被機器發現,是否能被未來的工具穩定讀取。
也就是說,RonnieCC 的下一步不是單純寫更多文章,而是讓每篇文章都走完整個交付鏈:從材料,到站內文章,到可被網路基礎設施讀取的公開知識物件。
結尾
這件事我本來以為只是修一個清單頁。但真正被修正的,是我對「發布」二字的理解。
發布不是讓文章能在瀏覽器裡被打開,而是讓文章進入一個可以被搜尋、被引用、被任何未來系統信任讀取的網路。
很多內容不是不夠好,只是一直沒有走完最後一哩。
如果你也在寫,問問自己:你的文章,真的交出去了嗎?